
中国AI“杀疯了”:Token调用量首超美国
炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
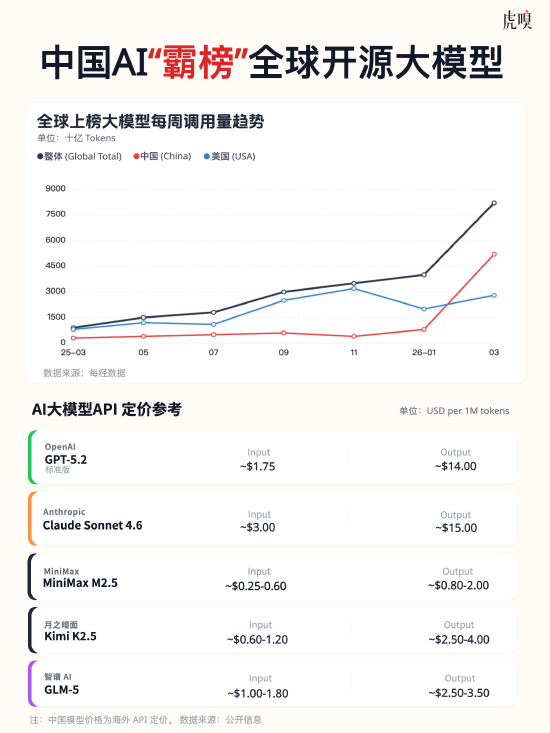
这两天,“中国AI模型的Token调用量首次超越美国”的新闻冲上了热搜。据全球最大API聚合平台OpenRouter的数据:2月9日-15日当周:中国模型调用量4.12万亿Token,美国2.94万亿,完成首次逆转。2月16日-22日当周:中国模型进一步增至5.16万亿Token(三周内增长127%),而美国模型回落至2.7万亿Token。
更令人振奋的是,在全球调用量排名前五的模型中,中国占据四席:MiniMax的M2.5、月之暗面的Kimi K2.5、智谱的GLM-5以及DeepSeek的V3.2。这四款模型合计贡献了Top5总调用量的85.7%。
为什么这个数据值得重视?
因为OpenRouter是目前全球最大的AI模型API聚合平台,拥有超过500万开发者用户,其API调用量数据被视为洞察全球AI应用落地趋势最真实的“晴雨表”。
最关键的是,该平台的用户主要由海外开发者构成——美国用户占比高达47.17%,而中国开发者仅占6.01%。这意味着,中国大模型的反超不是“自嗨”数据,而是全球开发者“用脚投票”的真实选择。
那中国大模型,为何实现了反超?
第一,是极致性价比。以输入100万Token为例,MiniMax和智谱的收费仅0.3美元,而海外主流对标产品(如Claude Opus)则高达5美元,是中国模型的约16.7倍。对于初创公司和开发者来说,这不仅是省钱,是生存。
第二,技术架构的“降本增效”。中国模型普遍采用MoE架构,也是能大幅度降低成本的原因。传统模型像全班同学一起做题,浪费算力;MoE架构像分小组作业,只让最擅长的“专家”参与计算。这种“按需激活”模式,让推理时的显存占用降低60%,吞吐量提升19倍。
第三,Token消耗的底层逻辑从“对话型”变成了“流程型”。过去AI是“问答工具”,一轮对话消耗几百到几千Token;现在AI是“数字员工”,单次任务可能消耗数十万Token。
需要说明的是,调用量的领先并不等同于技术的全面领跑。今天中国AI的发展,仍面临着基础理论的原创性不足等一系列挑战。这场超越不是终点,而是起点。
文案|张洪雷
编辑|华思雨
制图|管若潼
相关文章

