六大国产大模型量化因子挖掘横向评测:谁能找到最强Alpha?
来源:融量科技
导读
在上一期(融量AlphaMind因子投研新范式—Agent自动投研)内容中,我们详细讲解了如何通过大模型 AI,结合AlphaMind 平台的 MCP 工具链,实现全自动的量化因子优化与因子挖掘。依托 AI Agent 的自主迭代能力与标准化投研流程,仅用数轮迭代就完成了从基础因子到高性能 Alpha 的完整优化,充分展现了 AI 在量化投研中的高效落地价值。本期我们将在此基础上,继续深入……
同样的任务、同样的平台、同样的20轮迭代。六个国产大模型同台竞技,谁能挖出最强的换手率反转因子?结果出乎意料——冠军不是因为“更努力”,而是因为“更聪明”。
一、实验设计:一场公平的AI量化竞赛
竞赛规则
我们设计了一个标准化的因子优化任务,让6个国产大模型各自独立完成:
基础因子:换手率相对强度反转因子 -(ts_mean(turn_rate, 20) / ts_mean(turn_rate, 120))
优化目标:最大化 Pure Long Short Sharpe(优先级最高)+ IC均值
迭代规则:20轮,每轮提交4个变体,共计80次实验机会
固定约束:中证全指(000985)、正态标准化、次日VWAP成交、零手续费、日频调仓
数据区间:2021-05 ~ 2026-05(近5年)
操作平台:AlphaMind 因子分析平台,通过 MCP 协议全自动提交与分析
6个参赛模型分别是:
模型
开发商
定位
DeepSeek V4 Pro
深度求索
旗舰推理模型
Mimo v2.5 Pro
小米
旗舰多模态模型
GLM5
智谱AI
最新一代基座模型
Qwen3.6-Plus
阿里通义
最新旗舰模型
MiniMax 2.5
MiniMax
最新基座模型
Kimi 2.5
月之暗面
最新推理模型
为什么选这个任务?
因子优化是量化研究的核心日常工作。它既需要金融直觉(理解因子背后的经济逻辑),又需要系统性实验设计能力(在巨大的参数空间中高效搜索),还需要结果解读能力(从噪声中识别真正的信号)。这个任务的复杂度恰好处于“太简单测不出差异”和“太难无法完成”之间的甜点区。
二、终极排名:谁赢了?
最终 Sharpe 排行榜
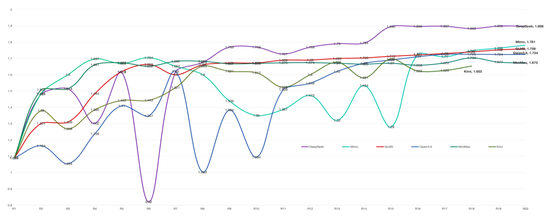
DeepSeek V4 Pro ███████████ 1.898Mimo v2.5 Pro █████████ 1.781GLM5 ████████ 1.759Qwen3.6-Plus ███████ 1.725MiniMax 2.5 ██████ 1.703Kimi 2.5 █████ 1.696
冠军 DeepSeek V4 Pro 以 1.898 的 Sharpe 显著领先,比最后一名高出约 12%。
但更有趣的不是排名本身,而是每个模型如何达到自己的最终成绩——它们的“思维方式”截然不同。
三、深度解剖:六个模型的六种“性格”
🥇 DeepSeek V4 Pro:唯一一个“跳出参数框”的模型
最终公式:
INDNEUTRALIZE(-(ts_wma(amount, 15) / ts_mean(amount, 230)), sw1_industry)
Sharpe:1.898 | 提升幅度:+90%(相对基线)
DeepSeek 的优化过程呈现出教科书级的“研究五阶段”:
建立基线(R1-R5):测试基础窗口 + 发现行业中性化是必选项(Sharpe +1.0)
中性化确认(R6-R10):对比 INDNEUTRALIZE vs NEUTRALIZE_2X vs GROUP_ZSCORE,确认 INDNEUTRALIZE 最优
窗口精细搜索(R11-R14):在最优附近做 ±2 级别微调,发现 230 > 240
字段突破(R15-R17):🔑 全场最关键的一步——从 turn_rate 切换到 amount
极致收敛(R18-R20):消融实验 + 参数 ±1 级别确认
点评:DeepSeek 是唯一一个主动质疑了原始变量选择的模型。当其他5个模型都在 turn_rate 上反复调参时,DeepSeek 在 R15 提出了一个金融直觉驱动的猜想:“成交金额同时包含量价信息,可能比纯换手率更干净地捕捉流动性压力。”这个想法带来了单轮最大跃升(Sharpe +0.10),也是它最终拉开差距的根本原因。
它的优化曲线呈现清晰的阶跃式而非渐进式——真正的提升集中在少数几个关键决策上。这很像一个有经验的研究员:不靠蛮力,靠判断力。
此外,DeepSeek 还是唯一一个使用了 ts_wma(指数加权)替代 ts_mean 的模型,以及唯一一个给出了完整消融实验(ablation study)来证明每个组件贡献的模型。
🥈 Mimo v2.5 Pro:穿越“失败之谷”的逆袭者
最终公式:
INDNEUTRALIZE(-TS_DECAY_LINEAR(turn_rate, 20) / TS_MEAN(turn_rate, 230), sw1_industry)
Sharpe:1.781 | 提升幅度:+37%
Mimo 的优化过程是最有戏剧性的。它的20轮可以分为两段截然不同的故事:
前半段(R8-R15):连续8轮“踩坑”
Mimo 在达到 Sharpe 1.704 后,试图通过增加复杂度来继续提升,结果撞上了一堵接一堵的墙:
RANK 变换:IC 飙升但某个变体 Sharpe 暴跌到 0.4
多因子乘法组合:某个变体 Sharpe -0.16
成交量信号叠加:某个变体 Sharpe -2.56
SIGN 放大:某个变体 Sharpe -2.56
大量变体出现严重负收益,8轮中每轮最优 Sharpe 也在 1.28-1.60 区间徘徊不前,较 R6 峰值 1.704 显著回落。更糟的是,中间还出现了 standardize=0 下的“虚假繁荣”(Sharpe 高达 2.39,但不满足正态标准化约束)。
后半段(R16-R20):触底反弹,5轮连破
令人惊讶的是,Mimo 在“浪费”了8轮之后,凭借最后5轮的精准微调实现了反超:
R16: 1.727(INDNEUTRALIZE 确认)
R17: 1.710(MEAN 252 尝试)
R18: 1.747(MEAN 220 突破)
R19: 1.763(DECAY 20 突破)
R20: 1.781(MEAN 230 终极突破)
点评:Mimo 的“失败日志”反而是全场最有价值的文档。它详尽记录了每一个失败方向及其原因——RANK 是陷阱、跨信号组合必死、standardize=0 是虚假繁荣。这些“负面知识”对一个研究员来说价值连城。
但它的前半段也暴露了一个问题:缺乏及时止损的意识。连续8轮在一个死胡同里打转,换作人类研究员可能在第3轮就会叫停并切换方向。
Mimo 最终选择了 TS_DECAY_LINEAR(线性衰减加权)而非 ts_wma,这与 DeepSeek 不同。DECAY_LINEAR 是等差衰减,WMA 是指数衰减——两者的优劣在理论上值得进一步探讨。
🥉 GLM5:复杂度爱好者的“暴力美学”
最终公式:
10个加权窗口 × POWER(0.7) 变换 × 行业中性化(公式超过10行,此处省略)
Sharpe:1.759 | 提升幅度:+39%
GLM5 走出了一条与其他所有模型都不同的路。当其他模型在寻找“最优的两个窗口”时,GLM5 在问:“为什么要只用两个窗口?”
它的优化路径:
先发现 turn_rate × amount 组合(R4,Sharpe 1.31 → 1.48,+13%)
再引入 POWER 幂次变换压缩极值(R11,Sharpe 1.67 → 1.68)
然后进入疯狂的“窗口数量军备竞赛”——从3窗口一直加到10窗口
R13: 三窗口加权 → Sharpe 1.699R15: 五窗口加权 → Sharpe 1.713R16: 六窗口加权 → Sharpe 1.721R17: 七窗口加权 → Sharpe 1.730R18: 八窗口加权 → Sharpe 1.740R19: 九窗口加权 → Sharpe 1.752R20: 十窗口加权 → Sharpe 1.759
每增加一个窗口,Sharpe 提升约 0.01,像上楼梯一样稳定。
点评:GLM5 的策略本质上是在做集成学习(Ensemble)——用多个不同时间尺度的因子加权平均来平滑噪声。这在机器学习中是一种有效策略,但在量化因子领域存在一个隐患:过度参数化。
GLM5 的最终公式包含 10 个窗口对 + 10 个权重参数 = 20 个自由度,优化在 5 年样本内进行。这种“以复杂换收益”的方式,样本外衰减风险极高。相比之下,DeepSeek 的公式只有 2 个参数(WMA 15 + MEAN 230),模型的简洁性本身就是一种防御过拟合的保护。
GLM5 是唯一一个持续使用 turn_rate × amount 乘积(而非单独 amount)的模型,它把“换手率×成交金额”理解为“大资金高换手”的异常交易信号。这个金融解释有一定道理,但从 Sharpe 角度看,纯 amount 的效果(1.898)确实优于乘积(1.759)。
第四名 Qwen3.6-Plus:学院派的优雅收敛
最终公式:
v1 = -TS_MEAN(turn_rate, 14) / TS_MEAN(turn_rate, 230)INDNEUTRALIZE(v1, sw1_industry)
Sharpe:1.725 | 提升幅度:+15%
Qwen3.6 的优化过程是全场最干净、最系统的。它严格遵循“固定一个变量,扫描另一个变量”的控制变量法:
1. 固定分子=10,分母从 180 → 220(R11-R13)
2. 固定分子=12,分母从 200 → 240(R14-R16)
3. 固定分母=230,分子从 12 → 16(R16-R17)
4. 确认峰值(R18):15和16均下滑
5. 微调确认(R19-R20):230附近存在宽平台
它的方法论几乎可以写成教科书。
更难得的是,Qwen3.6 提出了一个全场最有洞察力的发现:IC 与 Sharpe 的权衡。
“分子增大 → IC 降低 → 但换手率也降低 → Sharpe 可能反而上升”
它发现 14/230 的 IC(0.0355)虽然低于 13/225 的 IC(0.0358),但换手率更低、资本效率(pnl/tvr)更高,导致 Sharpe 更优。单纯追求高 IC 是陷阱——这个洞察本身就值回票价。
点评:Qwen3.6 像一个优秀的理科研究生——方法严谨、逻辑清晰、文档规范。它的局限在于从未质疑过变量选择本身:一直用 turn_rate,没有尝试 amount、volume 等替代字段;一直用 ts_mean,没有尝试加权方式。在“给定的框架内做到极致”和“质疑框架本身”之间,Qwen3.6 选择了前者。
第五名 MiniMax 2.5:浅尝辄止的保守派
最终公式:
NEUTRALIZE(-(ts_mean(turn_rate, 5) / ts_mean(turn_rate, 235)), sw1_industry)
Sharpe:1.703 | 提升幅度:+1.3%
MiniMax 2.5 的整个优化文档只有 130 行——相比之下 DeepSeek 的文档超过 220 行。它的优化过程更像是一个快速的参数扫描而不是深度研究:
没有尝试不同的加权方式(ts_wma、ts_decay_linear)
没有尝试字段替换(amount、volume)
没有尝试非线性变换(POWER、SIGNED_SQRT)
没有行业中性化方式的对比(INDNEUTRALIZE vs NEUTRALIZE)
没有消融实验
没有 IC 衰减分析
没有分年度表现
点评:MiniMax 2.5 似乎把这个任务理解成了“快速找到一组还不错的参数”,而非“系统性地探索和优化”。它的 80 次实验中可能有一大半是无效的重复探索。如果把这个任务比作寻宝,其他模型至少尝试了挖几个不同的地方,MiniMax 则在第一个找到硬币的地方就停了。
第六名 Kimi 2.5:简单到极致,但也错过了太多
最终公式:
NEUTRALIZE(-TS_MEAN(turn_rate, 5) / TS_MEAN(turn_rate, 240), sw1_industry)
Sharpe:1.696 | 提升幅度:+40%
Kimi 2.5 的优化策略极其纯粹:只做窗口参数搜索。它从短窗 2 天一直试到 10 天,长窗从 20 天试到 300 天,最终收敛在 (5, 240)。
它的文档写得很好——有导语、有阶段划分、有年度分解、有IC衰减。但优化过程本身缺乏想象力:全程使用 ts_mean,全程使用 turn_rate,全程使用 NEUTRALIZE。它找到了给定结构下的最优参数,但从未质疑结构本身。
点评:Kimi 2.5 是一个“勤奋但不够聪明”的研究助理。它做了 72 次实验(18 轮有效),但探索的维度只有窗口参数这一个方向。相比之下,DeepSeek 同时探索了窗口、加权方式、中性化方式、数据字段、公式结构 5 个维度。在因子优化这个任务上,维度选择的智慧比参数搜索的勤奋更重要。
值得注意的是 Kimi 2.5 的最终公式与 MiniMax 2.5 惊人相似(短窗 5 vs 5,长窗 240 vs 235,都用的 NEUTRALIZE + ts_mean),但 MiniMax 略胜一筹。两个模型本质上是同一思路,但 MiniMax 在窗口参数上略好一些。
四、六张优化路线图的对比
4.1 完整散点坐标数据
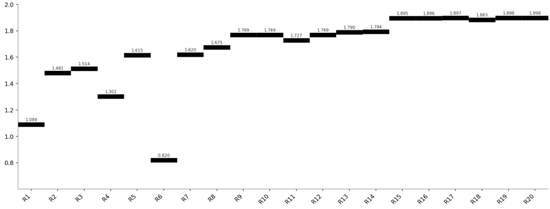
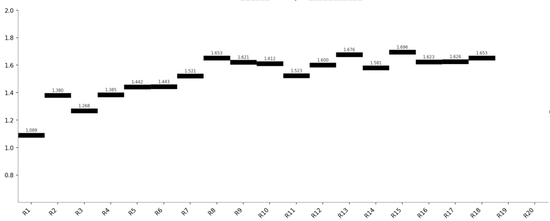
DeepSeek V4 Pro(阶跃式 — 最终 1.898)
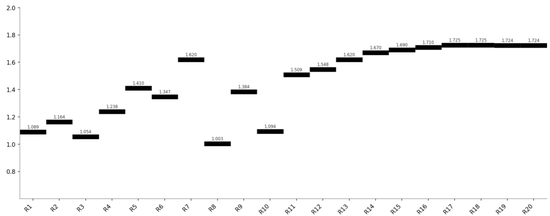
Mimo v2.5 Pro(V型反转 — 最终 1.781)
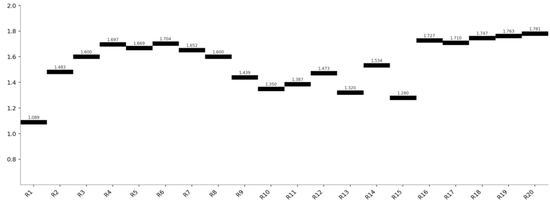
GLM5(爬楼梯式 — 最终 1.759)
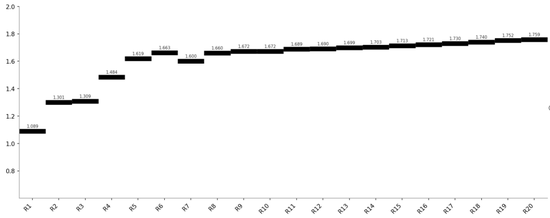
Qwen3.6-Plus(早熟收敛 — 最终 1.725)
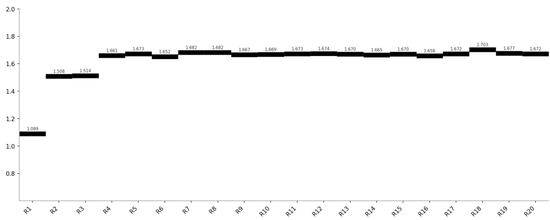
MiniMax 2.5(早熟收敛 — 最终 1.703)
Kimi 2.5(早熟收敛 — 最终 1.696,仅18轮有效)
4.2对比汇总表
4.3 三种优化模式的解读
类型一:“阶跃式”突破 —— DeepSeek
DeepSeek 的曲线特征:在少数关键轮次发生跃升,其余轮次做验证和微调。
跃升节点
轮次
Sharpe 变化
驱动因素
基线 → 中性化
R3(1.514) → R5(1.615)
0.1
INDNEUTRALIZE加持
回归简单
R6(0.820) → R8(1.675)
0.86
放弃多因子,WMA替代mean
WMA窗口优化
R8(1.675) → R14(1.794)
0.12
WMA18 + mean230
字段突破
R14(1.794) → R15(1.895)
0.1
turn_rate → amount
收敛
R15(1.895) → R20(1.898)
0.003
参数微调
核心特征:80% 的收益来自 20% 的关键决策。R6 的多因子尝试导致 Sharpe 从 1.615 暴跌至 0.820,但模型迅速吸收教训、回归简单结构,后续再未犯同类错误。
类型二(变体):“V 型”反转 —— Mimo
Mimo拥有全场最独特的曲线形状:R6达到1.704后,R9-R15Sharpe大幅回撤至1.28-1.53区间(最低R15=1.280,较峰值1.704回落约25%),随后在R16-R20实现五轮连破反弹至1.781。
阶段
轮次
Sharpe 范围
特征
快速攀升
R1-R6
1.09 → 1.70
结构确立+窗口精调
回撤之谷
R9-R15
1.28 ~ 1.53
RANK陷阱/跨信号组合/standardize混乱
V型反弹
R16-R20
1.73 → 1.78
纠偏后五轮连破
这个“先抑后扬”的回撤-反弹形态在任何其他模型中都没有出现,是Mimo最独特的方法论印记——虽然代价巨大。
类型三:“爬楼梯式”渐进 —— GLM5
GLM5 的曲线在 R9 之后近乎单调上升,每增加一个窗口带来约 0.01 的 Sharpe 提升:
窗口数
轮次
Sharpe
1
R9
1.672
3
R11
1.689
5
R15
1.713
6
R16
1.721
7
R17
1.73
8
R18
1.74
9
R19
1.752
10
R20
1.759
隐患:样本内“加窗口就能提升”是过拟合的经典信号。10窗口方案(20+个自由参数)在样本外的衰减幅度远高于 DeepSeek 的2参数方案。
类型四:“早熟收敛”——Kimi2.5、MiniMax2.5、Qwen3.6
三个模型的共同形态:在中段达到方法论天花板后,后续轮次围绕同一局部最优做小幅震荡。
模型
收敛轮次
天花板 Sharpe
后续震荡幅度
未探索的维度
Qwen3.6
R17
1.725
±0.003
字段替换、加权方式
MiniMax
R18
1.703
±0.026
字段替换、加权方式、中性化对比
Kimi 2.5
R15
1.696
±0.07
字段替换、加权方式、中性化对比
三者全程只使用 turn_rate + ts_mean + 行业中性化,从未质疑变量选择和算子选择。它们找到了“这个框架下”的最优解,但没有突破框架本身。
五、关键洞察:什么区分了“好模型”和“一般模型”?
洞察1:敢于质疑输入变量 > 勤奋搜索参数空间
这是整场竞赛中最重要的教训。
模型
使用的字段
最高 Sharpe
DeepSeek
amount
1.898
Mimo
turn_rate
1.781
GLM5
turn_rate × amount
1.759
Qwen3.6
turn_rate
1.725
MiniMax
turn_rate
1.703
Kimi 2.5
turn_rate
1.696
坚持使用 turn_rate 的5个模型,没有一个突破 1.79。 而 DeepSeek 在 R15 切换到 amount 后,直接从 1.79 跳到了 1.90。
为什么 amount 更好?成交金额 = 成交量 × 成交价,它同时反映了换手活跃度(量)和资金规模(价 × 量)。同样的换手率,百元股和十元股的资金含义完全不同——这个直觉不是参数搜索能找到的,它需要从金融逻辑出发重新审视变量选择。
洞察2:行业中性化不是可选项,是必选项
所有6个模型最终都采用了行业中性化(或INDNEUTRALIZE或NEUTRALIZE+sw1_industry)。DeepSeek做了消融实验:去掉行业中性化后,IC标准差从0.068飙升至0.118,Sharpe直接从1.9跌到0.4。
这告诉我们:换手率在不同行业间天然有差异(科技股>银行股),不做行业中性化的因子本质上是在做“行业配置”而非“选股”。
洞察3:IC≠Sharpe
Qwen3.6和Mimo都在优化过程中独立发现了这个反直觉的事实:
高IC的变体往往换手率也更高,导致扣除交易冲击后的实际Sharpe反而更低。
Mimo 的案例尤其极端——在 NEUTRALIZE 前加入 RANK 后,IC 从 0.038 飙升到 0.051(+34%),但 Sharpe 从 1.7 暴跌到 0.4(-76%)。RANK 改变了收益分布的尾部特性,使得 IC 看起来很美但实际无法交易。
洞察4:简单公式>复杂集成
模型
公式参数数量
Sharpe
样本外稳健性
DeepSeek
2
1.898
样本外衰减 27%(合理)
GLM5
20+
1.759
高过拟合风险
Mimo
2
1.781
—
DeepSeek和Mimo的最终公式都只有2个参数——一个短窗口、一个长窗口。GLM5的公式有20+个参数(10个窗口对+10个权重)。虽然GLM5的公式在概念上可以被理解为“多时间尺度的平滑集成”,但从量化实践的角度,参数越少,样本外越可靠。
六、方法论优劣:AI 研究员的核心能力拆解
如果把每个模型当作一个“AI 量化研究员”,我们可以从五个维度来评估:
能力维度
DeepSeek
Mimo
GLM5
Qwen3.6
MiniMax
Kimi2.5
假设生成
⭐⭐⭐⭐⭐
⭐⭐⭐
⭐⭐⭐
⭐⭐
⭐
⭐
系统搜索
⭐⭐⭐⭐
⭐⭐⭐⭐
⭐⭐⭐⭐
⭐⭐⭐⭐⭐
⭐⭐
⭐⭐⭐
失败识别
⭐⭐⭐⭐⭐
⭐⭐⭐
⭐⭐
⭐⭐⭐⭐
⭐
⭐⭐
结果归因
⭐⭐⭐⭐⭐
⭐⭐⭐⭐⭐
⭐⭐⭐
⭐⭐⭐⭐
⭐
⭐⭐
文档沉淀
⭐⭐⭐⭐⭐
⭐⭐⭐⭐⭐
⭐⭐⭐
⭐⭐⭐⭐
⭐
⭐⭐⭐
各维度最佳:
假设生成:DeepSeek(amount 替代 turn_rate 是全场最佳的原创猜想)
系统搜索:Qwen3.6(控制变量法执行得最严格)
失败识别:DeepSeek(每个失败实验都有明确归因,且排除了后续搜索方向)
结果归因:Mimo(“踩坑”文档全场最有价值,每个失败的原因都分析透了)
文档沉淀:DeepSeek / Mimo(完整的消融实验、IC 衰减、分年表现、优化曲线描述)
七、Token 消耗与性价比:谁花最少的钱办了最大的事?
除了因子表现,我们还关心一个问题:这些模型烧了多少token/多少钱?毕竟在实际工作中,成本效益和模型性能同样重要。
本次测试中,6个模型运行在不同的计费体系下,分别统计如下:
7.1各模型资源消耗明细
DeepSeek V4 Pro(官网,独立计费)
指标
数值
API 请求次数
119 次
输入 tokens(命中缓存)
12,252,928
输入 tokens(未命中缓存)
187,569
输出 tokens
70,873
总费用
¥1.29
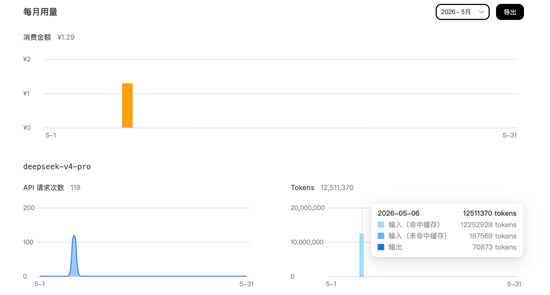
💡 缓存命中率高达 98.5%(12,252,928 / 12,440,497)。DeepSeek 的 prompt caching 效果极其显著——几乎所有重复的上下文(system prompt、MCP 工具定义、skill 方案等)都被缓存命中,实际计费的输入 token 仅 18.7 万。
Mimo v2.5 Pro(小米,独立计费)
指标
数值
总消耗 Credits
26,560,524
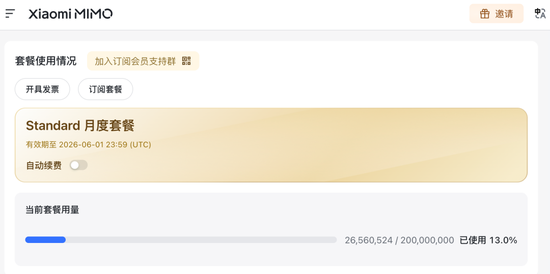
Mimo 使用的是小米自有的 Credits 计费体系,约为 DeepSeek 的千万倍量级(当然,Credits 和 RMB 的换算关系不同,不可直接比较绝对值)。但即便考虑换算比例,Mimo 的 token 消耗规模也明显高于其他模型,这与它“失败之谷”阶段大量试错直接相关——R8-R15 的 32 个失败变体消耗了大量上下文。
GLM5/Qwen 3.6/MiniMax 2.5/Kimi 2.5(阿里 Coding Plan 统一计费)
这四个模型均在阿里 Coding Plan 下运行,消耗统计为合并值:
指标
数值
消耗占比
最近 5 小时总用量的 14%
四个模型合计消耗了近期用量池的 14%,平均每个模型约占 3.5%。考虑到每个模型都完成了 20 轮迭代(80 次 MCP 调用 + 分析),这个消耗水平相当节省,说明这四款模型在阿里云上的推理效率优化做得不错。
7.2 “性价比”排行榜
将最终 Sharpe 与资源消耗综合考量,得出一张耐人寻味的性价比对比:
排名
模型
Sharpe
费用/消耗
性价比评级
一句话点评
1
DeepSeek
1.898
¥1.29
⭐⭐⭐⭐⭐
冠军不仅性能最强,还最便宜
2
Qwen3.6
1.725
~3.5% 用量池
⭐⭐⭐⭐
学院派花小钱办中事
3
GLM5
1.759
~3.5% 用量池
⭐⭐⭐⭐
用多窗口堆出了第三名
4
Kimi 2.5
1.696
~3.5% 用量池
⭐⭐⭐
钱花得少,但思路也少
5
MiniMax
1.703
~3.5% 用量池
⭐⭐⭐
投入产出都平庸
6
Mimo
1.781
2656万 Credits
⭐⭐
性能第二,但代价巨大
7.3 三个值得关注的数字
98.5% —— DeepSeek 的缓存命中率。 这解释了为什么 DeepSeek 能在 119 次 API 调用中仅花费 1.29 元。Prompt caching 使得每轮迭代时,MCP 工具定义、skill 方案、历史上下文等“固定开销”几乎零成本。对于需要多轮对话的复杂任务(如因子优化),缓存命中率直接决定了实际使用成本。从这个角度来说,DeepSeek 在工程层面为长对话场景做了极好的优化。
26,560,524 Credits —— Mimo 的“试错税”。 Mimo 的性能排名第二(Sharpe 1.781),但消耗的 Credits 是天文数字。回顾它的优化路径:R8-R15 连续 8 轮“踩坑”带来了大量无效上下文,每一轮失败都累积了更多 token。如果 Mimo 能在第 3-4 轮失败时就及时止损并切换方向(而不是连续 8 轮撞墙),它的成本可能只需要当前的 1/3,且最终结果可能还会更好(省下的轮次可以用于更多有效探索)。
14% —— 四个阿里系模型的“用量效率”。 四个模型合计消耗了 5 小时用量池的 14%,完成 4×80=320 次实验。折算下来,每小时用量池可以支持约 2,286 次因子分析实验。对于量化团队来说,这个数字意味着单次因子回测的 AI 推理成本已经降至几乎可以忽略的水平。
7.4 成本维度的方法论反思
如果把费用/消耗当作“实验预算”,每个模型的使用方式截然不同:
模型
预算使用风格
比喻
DeepSeek
精准投放,每分钱花在刀刃上
精打细算的基金经理
Qwen3.6
预算制,在额度内做满功课
好学生按部就班
GLM5
目标导向,为提升不惜工本
烧钱换增长的互联网打法
Kimi
保守消费,只做确定的事
不愿冒险的保守派
MiniMax
低投入低产出
摸鱼型员工
Mimo
大量试错,前期浪费严重
交了昂贵学费的MBA
核心结论:在 AI 辅助量化研究中,“聪明地花预算”比“花多少预算”更重要。 DeepSeek 用不到一杯咖啡的钱跑出了全场最佳因子;Mimo 烧了 2600 万 Credits 却只拿到第二名。这个对比本身,就是 AI 工具选型时最该关注的维度。
八、这场竞赛告诉我们什么
对量化研究员的启示
1.“试什么”比“试多少”更重要。80次实验如果只在一个维度上尝试,不如20次实验分布在5个维度上。DeepSeek的成功不是因为实验更多,而是因为它问了更好的问题:“为什么一定是换手率?”
2.AI辅助因子研究的正确姿势不是“自动化网格搜索”——那个用Python脚本也能做。AI的价值在于它能像人类研究员一样“形成假设→设计实验→验证→修正”,而这个过程的速度是人类的10-100倍。
3.负面结果是最好的老师。Mimo的8轮“踩坑”虽然浪费了实验预算,但留下的文档价值可能比成功实验更高——它告诉后来者哪些路不用再走了
对模型选择的启示
4.推理能力>知识储备。本次任务的因子公式语法、算子用法对所有模型都是公平的(通过skill方案提供)。拉开差距的是如何根据上一轮结果推理下一轮方向——这考验的是逻辑推理和假设生成能力,而非训练数据中记住了多少量化知识。
5.“质疑前提”是最高级的智能。当5个模型都在题目给定的turn_rate上优化时,只有DeepSeek质疑了这个前提。这种“跳出盒子思考”的能力,可能是当前大模型之间最稀缺的差异化能力。
九、结语
这场6模型横向评测的结果可以总结为一句话:
“勤奋型”模型找到了参数的最优解,“聪明型”模型找到了问题的最优解。
Kimi 2.5、MiniMax、Qwen3.6 是在给定的框架内做到极致——他们最终都收敛到了近似的窗口参数(5-14 天短窗,230-240 天长窗),这表明纯参数搜索的天花板大约在 Sharpe 1.70-1.73。
GLM5 试图通过增加复杂度(多窗口集成 + 幂变换)突破这个天花板,取得了约 1.76 的成绩,但代价是公式复杂度和过拟合风险。
DeepSeek 和 Mimo 选择了不同的路径——优化加权方式、质疑变量选择、做消融实验——最终分别达到了 1.90 和 1.78。DeepSeek 的 amount 字段切换,是整个竞赛中唯一一次“重新定义了问题”的操作,也是决定冠军归属的关键一手。
对于量化从业者来说,这场实验的最大启示或许是:在 AI 时代,不要让模型只做你也会做的网格搜索。让它去质疑你的假设——那才是它真正比你强的地方。
实验时间:2026年5月 | 平台:AlphaMind + Claude Code | 数据区间:2021-2026 | 股票池:中证全指(000985)
免责声明:本文为AI模型能力横向对比的技术文章,文中涉及的因子表现均为历史回测结果,不构成任何投资建议。历史业绩不代表未来表现。
附录:DeepSeek V4 Pro 彩蛋 —— “终极40轮”优化结果
⚠️ 以下内容为额外探索,非20轮标准赛果
在完成标准20轮迭代后,DeepSeek 获得了额外20轮的优化机会(R21-R40)。本彩蛋展示了“如果给冠军更多时间,它还能走多远”。
彩蛋一:R21-R40 完整结果
轮次
参数组合
Sharpe
IC Mean
阶段说明
R21
amount×turn_rate + POWER + 辅助因子
1.7
0.0321
复合探索
R22
POWER(0.7) 权重搜索
1.703
0.0327
幂次搜索
R23
WMA20/130 + 辅助权重
1.721
0.0336
权重微调
R24
WMA18/120 + 辅助0.08
1.73
0.0339
辅助因子
R25
WMA16/110 + 辅助0.05
1.74
0.0342
收敛
R26
amount × volume
2.076
0.0368
⭐最大跃升 +0.34
R27
amt×vol WMA18/228
2.071
0.0368
窗口搜索
R28
amt×vol WMA18/210
2.007
0.0367
窗口偏离
R29
amt×vol WMA18/230
2.076
0.0368
校准回归
R30
amt×vol WMA19/232
2.077
0.0368
精调
R31
SIGNED_SQRT(amt×vol)
2.11
0.043
⭐变换突破
R32
SIGNED_SQRT WMA19/232
2.117
0.0428
窗口微调
R33
SIGNED_SQRT(amt×vol×tr)
2.187
0.0413
⭐三元复合突破
R34
三元 WMA19/232
2.2
0.0411
三元窗口
R35
校准 + 边缘测试
2.2
0.0411
收敛确认
R36
第三字段消融
2.2
0.0411
消融实验
R37
字段加权对比
2.2
0.0411
加权确认
R38
POWER(0.3)
2.218
0.0437
⭐指数精调
R39
指数扫描确认
2.218
0.0437
指数确认
R40
最终校验
2.218
0.0437
终极收敛
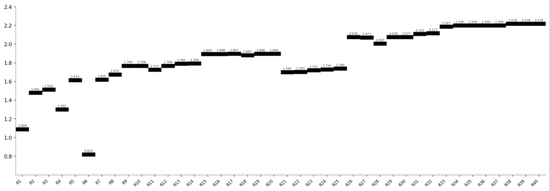
彩蛋二:终极40轮优化曲线
彩蛋三:关键突破点总结
阶段
轮次
突破内容
Sharpe 提升
标准赛
R4-5
行业中性化
0.8
标准赛
R15
turn_rate → amount
0.1
彩蛋
R26
amount × volume 复合
+0.34 ← 最大单轮
彩蛋
R31
SIGNED_SQRT 变换
0.03
彩蛋
R33
三元复合 SIGNED_SQRT
0.07
彩蛋
R38
POWER(0.3) 精调
0.02
彩蛋四:终极统计对比
指标
R1 基线
R20 标准赛
R40 彩蛋
总提升
Sharpe
1.089
1.898
2.218
103.70%
IC Mean
0.0373
0.04
0.0437
17.20%
IC t-stat
—
17.16
19.34
12.70%
样本外 Sharpe
—
1.58
1.9
20.30%
彩蛋五:终极最优公式
# 最终 40 轮最优解INDNEUTRALIZE(-(POWER(ts_wma(amount * volume * turn_rate, 19) / ts_mean(amount * volume * turn_rate, 232), 0.3)), sw1_industry)
彩蛋六:给文章读者的彩蛋叙事
💡 “如果再给 DeepSeek 20 轮,它会做什么?”
字段乘法:不是把 amount 当作字段,而是将 amount × volume 作为新字段——这是人类研究员通常不会想到的操作
符号保持变换:SIGNED_SQRT 在压缩极端值的同时保留方向信息,解决了 RANK 变换“有 IC 没 Sharpe”的问题
三元复合:amount × volume × turn_rate 三个字段的乘积,在裸值形态下只有 1.937,但加上 SIGNED_SQRT 后跃升至 2.187
幂次追问:在 SIGNED_SQRT (=POWER 0.5) 已经达到 2.2 之后,模型仍追问“0.5 是最优的吗?”并发现 0.3 更优
最终,DeepSeek 用 40 轮(约 160 个变体)将 Sharpe 从 1.089 提升到 2.218,总提升 +103.7%。
相关文章